










DeepSeek-OCR: ثورة في ضغط المستندات البصرية تتجاوز 10 أضعاف

أعلنت شركة DeepSeek مؤخرًا عن إنجاز تقني يمثل نقطة تحول في عالم التعرف البصري على الحروف (OCR) والتعامل مع السياقات الطويلة لـ النماذج اللغوية الكبيرة (LLMs). هذا الإنجاز، الذي يحمل اسم DeepSeek-OCR، لا يقتصر على كونه أداة متقدمة لاستخراج النصوص، بل هو نظام مبتكر يتيح ضغط المستندات النصية بصريًا بما يصل إلى 10 أضعاف حجمها الأصلي مع الحفاظ على دقة شبه مثالية.
ما هو DeepSeek-OCR؟
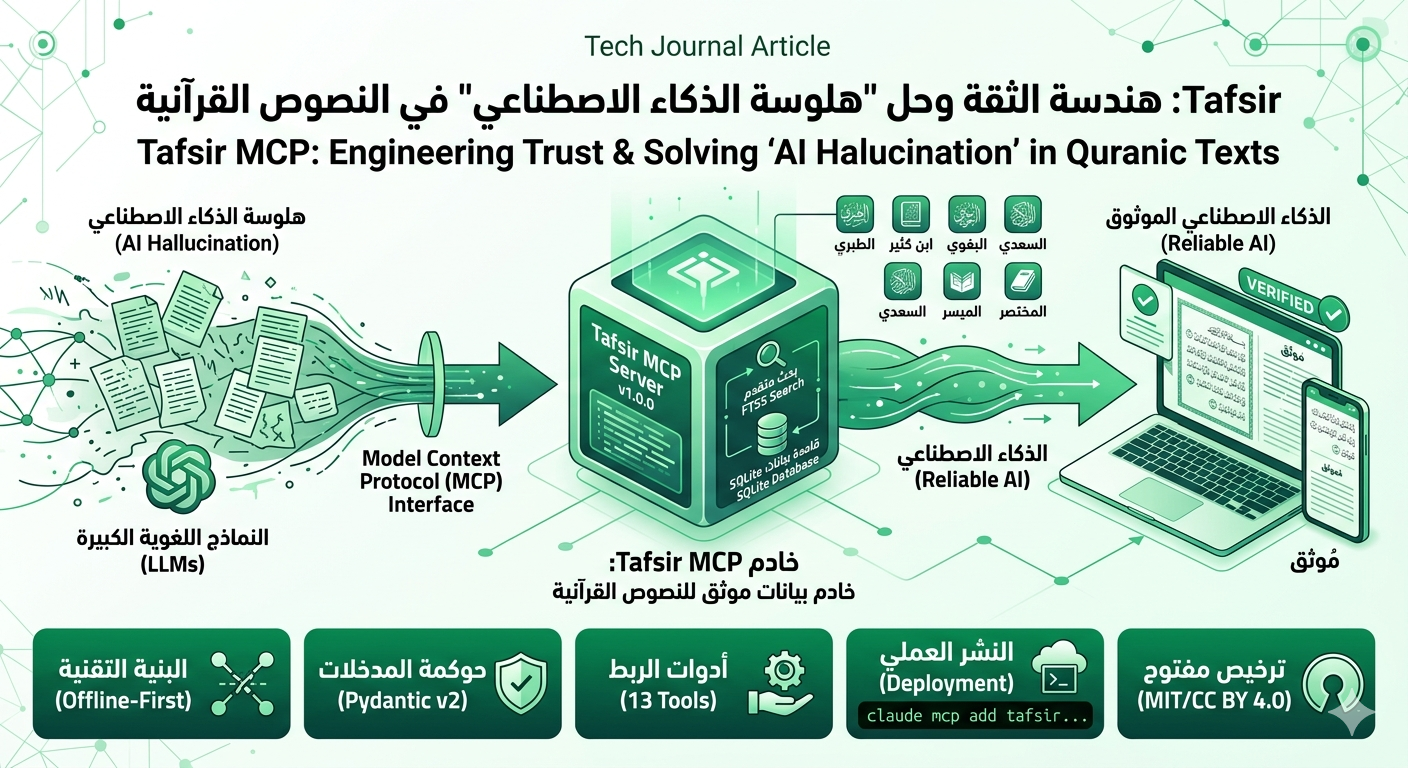
DeepSeek-OCR هو نظام متعدد الوسائط (Multimodal System) مصمم خصيصًا لقراءة وفهم المستندات المصورة (مثل صفحات الكتب الممسوحة ضوئيًا أو ملفات PDF) بكفاءة غير مسبوقة. يكمن جوهر ابتكار هذا النظام في تقنية تسمى “الضغط البصري للسياق” (Context Optical Compression).
المبدأ الجذري للضغط البصري
في النماذج اللغوية التقليدية، يتم تمثيل الكلمات والجمل في شكل رموز نصية (Text Tokens). كلما زاد حجم النص، زاد عدد الرموز المطلوبة، مما يؤدي إلى:
- استهلاك كبير لموارد الحوسبة (GPU Memory).
- إطالة زمن معالجة السياق (Context Window).
على النقيض من ذلك، يعالج DeepSeek-OCR النص عن طريق تحويله إلى تمثيل بصري مضغوط يُطلق عليه الرموز البصرية (Vision Tokens). - الإنجاز: يتمكن DeepSeek-OCR من تمثيل كمية من المعلومات تحتاج إلى حوالي 1000 رمز نصي باستخدام ما يقرب من 100 رمز بصري فقط.
- الدقة: عند نسبة ضغط تصل إلى 10 أضعاف، يحقق النظام دقة فك تشفير (OCR Precision) تتجاوز 96%، مما يعني ضغطًا شبه غير مُهدر للمعلومات.
نسبة الضغط (تقريباً) الدقة في استعادة النص (OCR Precision)
\text{9x – 10x} \approx 96\% – 97\% (شبه مثالية)
\text{20x} \approx 60\%
كيف يحقق DeepSeek-OCR هذا الإنجاز؟
يتكون DeepSeek-OCR من مكونين رئيسيين يعملان بتناغم:- DeepEncoder (المُشفر العميق)
هذا المكون هو القلب النابض لعملية الضغط. مهمته هي معالجة صورة المستند عالية الدقة (مثل صفحة PDF كاملة) وضغطها جذريًا إلى عدد قليل جدًا من الرموز البصرية ذات الكثافة المعلوماتية العالية. يقوم المُشفر بترميز ليس فقط الأحرف، بل أيضًا تخطيط المستند (Layout)، والجداول، والأشكال، مما يجعله أداة لفهم بنية المستند وليس مجرد استخراج نصوصه. - DeepSeek3B-MoE (وحدة فك التشفير)
تستخدم DeepSeek نموذجًا صغيرًا وفعالاً من نوع Mixture of Experts (MoE) لفك تشفير الرموز البصرية المضغوطة وتحويلها مرة أخرى إلى نص منظم ونظيف (غالبًا بصيغة Markdown). تعمل هذه الوحدة على استعادة النص بدقة عالية بالاستفادة من كثافة المعلومات المخزنة في الرموز البصرية.
الآثار المترتبة على عالم الذكاء الاصطناعي 💡
هذا الابتكار له تبعات هائلة تتجاوز مجرد تحسين أدوات التعرف على الحروف التقليدية: - توسيع نافذة السياق (Context Window)
لعل الأثر الأهم هو تجاوز قيود حجم السياق في النماذج اللغوية الكبيرة. بدلاً من التعامل مع سياق مقيد بالرموز النصية، يمكن للنموذج الآن استيعاب كميات أكبر بكثير من المستندات في ذاكرته (التي قد تصل إلى ما يعادل 10-20 مليون رمز تقليدي)، مما يفتح الباب أمام “ذاكرة” شبه غير محدودة للنماذج. - تدريب نماذج الذكاء الاصطناعي بكفاءة
يمكن استخدام DeepSeek-OCR لتوليد كميات ضخمة من بيانات التدريب عالية الجودة والمُنظمة (Structured Data) للنماذج اللغوية بتكلفة ووقت أقل بكثير. تشير التقارير إلى قدرة النظام على معالجة أكثر من 200 ألف صفحة يوميًا على وحدة معالجة رسوميات واحدة (A100). - تطبيقات عملية متقدمة
يُمكن للتقنية الجديدة أن تُحدث ثورة في مجالات متعددة، مثل:
- الأرشفة الرقمية للوثائق التاريخية: ضغط وحفظ الأرشيفات الضخمة بكفاءة غير مسبوقة.
- التحليل المالي والقانوني: استخراج وتلخيص البيانات من العقود والفواتير والتقارير المالية بسرعة فائقة مع الحفاظ على التخطيط الهيكلي للمستند (الجداول، الأعمدة).
- الرعاية الصحية: معالجة الملاحظات الطبية المكتوبة بخط اليد أو النماذج المعقدة.
باختصار، يمثل DeepSeek-OCR نقطة تحول جوهرية. لقد أثبت أن الصورة (الرؤية) يمكن أن تحمل معلومات نصية أكثر كثافة وكفاءة مما كنا نعتقد، مما يفتح مسارًا جديدًا وفعالًا نحو بناء أنظمة ذكاء اصطناعي قادرة على فهم واستيعاب المستندات الطويلة والمعقدة بشكل غير مسبوق.
- DeepEncoder (المُشفر العميق)












إرسال التعليق